昨日からSplitTrieについての論文を読んでいる。 どうせ講義で説明する必要があるので、一旦ブログに書いて説明の練習&指針作り。 ブログの30分ルールは一旦破る。じっくり考えたいので。
パケットクラス分類における問題
ネットワークスイッチなどのネットワーク機器はパケットのヘッダを読み取り、 ルーティングや、FWでのブロック、QoS管理、ACLなどを行う。 パケットをどのように処理するかを決定するために、ネットワーク機器はルールセットを作成する。 そして、ルールセットはしばしば、トライ構造によって表現され、効率よくパケットヘッダのルールマッチングを行う。
従来ネットワークの場合、ルールの対象となるパケットのヘッダのフィールドはせいぜい5つだ。 具体的には、送信元IPアドレス、送信先IPアドレス、送信元ポート、送信先ポート、プロトコル番号だ(5-tuple)。 これらのヘッダーフィールドごとにルールが作成され、ルールセットに対しアクションが関連づけられる。 しかし、SDNなどではヘッダーフィールドが5つでは収まらない。 例えば、特定の部署を指定するフィールドや、ユーザーIDやグループを指定するフィールドなど、 さまざまなフィールドが追加される。 それにより、ルールセットがより複雑かつ巨大になり、トライ構造も複雑化、巨大化する。
ルールセットを表すトライ構造の複雑化、巨大化は、 パケット分類の効率を低下を引き起こす。 今後のネットワークにおいては、パケット分類をより効率よく行うアルゴリズムが必要となる。 それがSplitTrieだ。
SplitTrieとは
SplitTrieはトライ構造をField Type Vectorを元に分割することで、 ルールのオーバーラップを低減し、パケット分類の効率を向上するアルゴリズムだ。 特にトライ構造のアップデート効率を向上させることを目的としている。
Field Type Vectorは任意の閾値以上のフィールドをカバーするルールをBig Field(1), 以下をSmall Field(0)として、ルールを表現したものだ。 例えば、閾値80%でそれぞれのルールが以下のようなカバー率だった場合、Field Type Vectorは10010となる。
- 送信元IPアドレス: 90%
- 送信先IPアドレス: 1%
- 送信元ポート: 1%
- 送信先ポート: 80%
- プロトコル番号: 10%
フィールドが2つだった場合、00, 01, 10, 11の4つのField Type Vectorが存在する。 そして、それらによってトライ木は4つに分割される。 新しいルールを追加するなど、トライ構造のアップデートをする際には、 そのルールのField Type Vectorを計算し、それと一致するVectorを持ったトライ構造に追加ルールをマージする。
ルールのオーバーラップがトライ構造を複雑化する理由は?
カバー範囲が小さなルールが、大きなルールにオーバーラップされること(論文中ではOne-bigと言われる)で、 トライ構造に追加のノードが発生する。この追加のノードが、トライ構造を複雑化、巨大化させる。
ちなみにOne-bigは類似性があまり見られないルール同士が、同じトライ構造に存在する状態を作ると言えるだろう。
Field Type Vectorを用いたトライ構造の分割によってルールのオーバーラップが低減する理由は?
Field Type Vectorが同じであれば、それらのルールが似ている可能性が高い。 そのため、ノードの統合が進み、トライ構造が簡略化される。 例えば、cat, can, capという似た単語が集められた場合と、cat, dog, badという似ていない単語が集められた場合では、 それぞれ以下のようなトライ構造を作る。
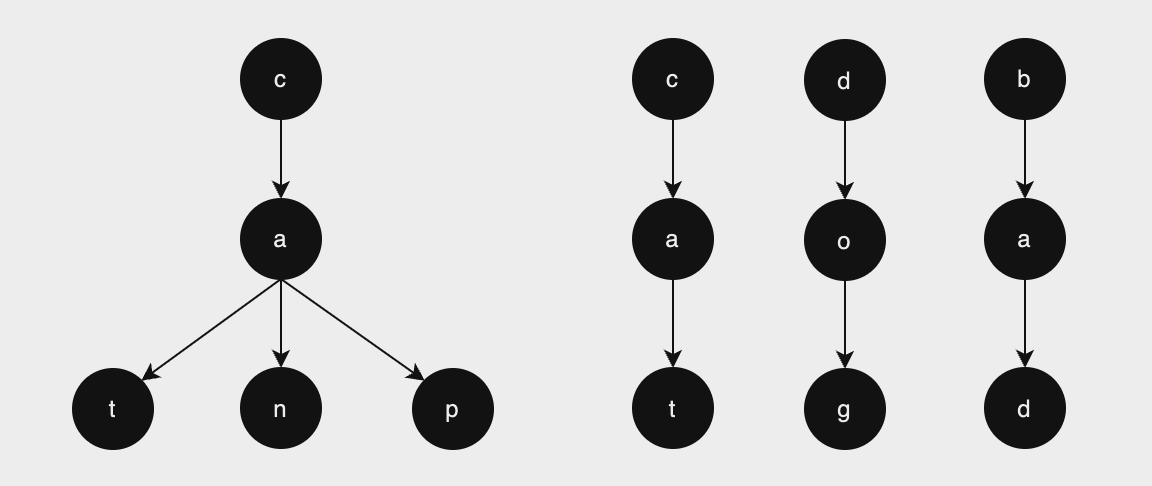
この例は簡単すぎるが、似たルールを集めた方がトライ構造のノードは少なくなるというのはこういうことだと思う。 ここで、トライ構造のアップデートを考える。 左の方にまた似た単語、例えばcabが追加される場合は単純にリーフにbノードを追加流だけで済む。 一方、右の方にまた似ていない単語、例えばanyが追加される場合は、まずaがルートの構造があるか探し、 その後、新たにaがルートの構造を作る必要がある。 確かに、似たもの同士を集めた方が効率は良さそうだ。
Field Type Vectorとルールの類似の関連性
ここまでくると、Field Type Vectorとルールの類似の関連性が気になる。 一応感覚的に類似しそうだなというのはある。
実験結果は?
元々オーバーラップが少ないシンプルなルールを持つセットに対しては、SplitTrieの効果はなかった。 対して、複雑なルールを持つセットに対しては、ノード数、lookup time、アップデートレイテンシの減少を確認したようだ。